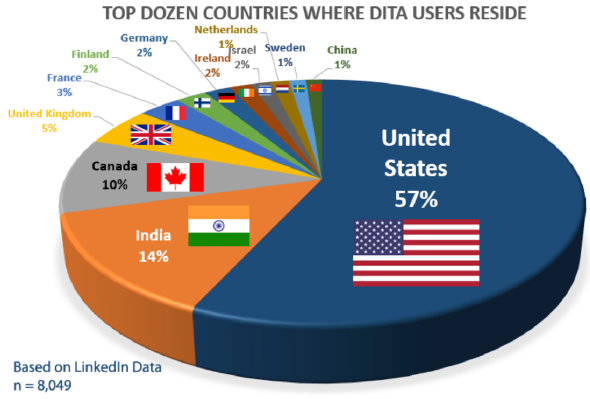
So, nach der ganzen DITA-Aufregung kommen wir nun zu etwas völlig anderem. Naja, ein bisschen DITA ist auch dabei, aber hey, ihr wisst, wo ihr hier lest 😉
Ich habe mir Jang Graats Vortrag „Faster than agile“ angeschaut. Gerade bin ich wieder mittendrin in einem agilen Projekt und da klang das doch vielversprechend.
Vorab muss ich sagen, dass ich das Agile-Bashing hier etwas arg konstruiert fand. Jang kritisierte, dass wir als Redakteure in agilen SW-Projekten schnell dabei sind die ganzen Arbeitsweisen der Entwickler zu übernehmen: Versionsverwaltung, Nightly builds… Worum es ihm aber eigentlich geht ist, dass wir Redakteure uns von diesem Publikationsparadigma verabschieden sollen, d.h. zu einem definierten Zeitpunkt generieren wir alle Publikationen und liefern sie dann aus.
Live-Content statt Publikation
Die Probleme fangen da an: wenn man für mehrere Produkte, Variante, Endgeräte, Zielgruppen und Sprachen generiert, kommt schnell eine beachtliche Menge zusammen, die bei Updates publiziert werden muss. Das nimmt zum Einen viel Zeit in Anspruch und zum Anderen benötigt man viel Speicherplatz für die Vielzahl von Publikationen.
Seine Lösung für die Zukunft ist das Live-Publishing von Content on demand, d.h. in dem Moment in dem ein Nutzer, die Seite aufruft, wird sie per XSLT generiert und angezeigt. Der XML-Content (hier war es DITA, was hier aber sekundär ist) liegt hierbei direkt auf dem Server. So bekommt der Nutzer absolut frischen Content und wir Redakteure müssen nicht mehr dem Umweg über Publizieren und dann Builds machen, sondern können Content-Änderungen direkt in die Welt raushauen. Zudem ist der Content direkt auf den Nutzer zugeschnitten, auf sein Endgerät, seine Sprache etc.
Dazu stellte Jang auch einen Workflow vor, bei dem er über das HTML5-Attribut editable eine Möglichkeit gefunden hat, auch die generierte Seite zu bearbeiten und die Änderungen wieder in den DITA-Quelldatei zurück zu überführen. Was gerade bei kleinen Änderungen oder auch Reviews eine ziemlich praktische Angelegenheit ist, denn diese könnte man so sehr einfach auch SMEs machen lassen, ohne dass diese sich mit XML-Dateien herumschlagen müssen.
Und wie geht das?
Leider hab ich in dem Vortrag wirklich konkrete Ausführungen dazu vermisst, wie das ganze gelöst ist, wie der komplette Prozess im Detail aussieht (auch technisch gesehen), wie ich die DITA-Files organisiere, mit was publiziert wird. So war der Vortrag erst einmal nur ein kleiner Anstoß zum Überdenken schon ziemlich etablierter Arbeitsweisen und dass es auch anders geht.
Ich hoffe, dass es bald konkreter wird – zumindest hat Jang angedeutet, dass er da eine richtige Lösung bauen (anbieten?) will. Ich werde mir diese Möglichkeit in den nächsten Wochen jedenfalls auch mal genauer anschauen.
(Als ich übrigens einem Entwickler von diesem XSLT-On-Demand-Web-Publishing erzählte, schlug der allerdings die Hände über dem Kopf zusammen: Das gäbe doch nur Performance-Probleme und potentielle Sicherheitslücken. )